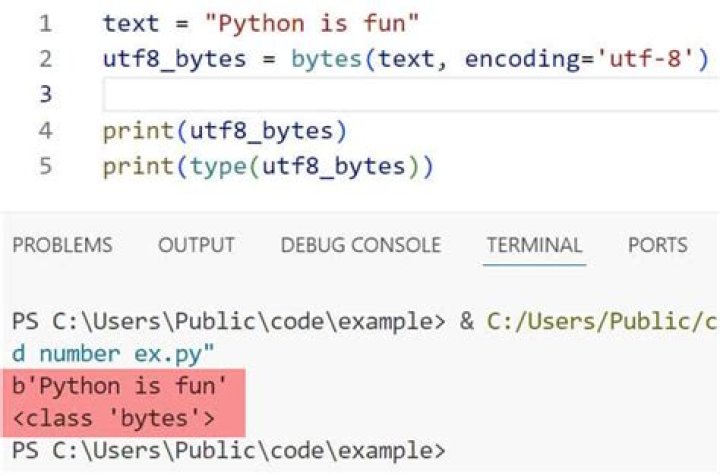
How to write unicode text to a text file in Python
- unicode_text = u’ʑʒʓʔʕʗʘʙʚʛʜʝʞ’
- encoded_unicode = unicode_text. encode(“utf8”)
- a_file = open(“textfile.txt”, “wb”)
- a_file. write(encoded_unicode)
- a_file = open(“textfile.txt”, “r”) r reads contents of a file.
- contents = a_file. read()
- print(contents)
How do you read and write UTF-8 in Python?
See the codecs module for the list of supported encodings. So by adding encoding=’utf-8′ as a parameter to the open function, the file reading and writing is all done as utf8 (which is also now the default encoding of everything done in Python.)
How do you specify encoding in Python?
In the source header you can declare: #!/usr/bin/env python # -*- coding: utf-8 -*- …. This declaration is not needed in Python 3 as UTF-8 is the default source encoding (see PEP 3120). In addition, it may be worth verifying that your text editor properly encodes your code in UTF-8.
How do I encode in UTF-8?
If you’re still having encoding issues, you can try these steps:
- Find the file.
- Right click on the file | click Open With.
- Click Notepad.
- Click File | then Save As.
- Navigate to the folder where you want to save your file.
- Provide a name for your file.
- Add .
- Make sure that the encoding is set to UTF-8.
How do you read encoded text in Python?
decode() is a method specified in Strings in Python 2. This method is used to convert from one encoding scheme, in which argument string is encoded to the desired encoding scheme. This works opposite to the encode. It accepts the encoding of the encoding string to decode it and returns the original string.
What does UTF-8 encoding do?
UTF-8 is an encoding system for Unicode. It can translate any Unicode character to a matching unique binary string, and can also translate the binary string back to a Unicode character. This is the meaning of “UTF”, or “Unicode Transformation Format.”
Is UTF-8 and ascii same?
UTF-8 encodes Unicode characters into a sequence of 8-bit bytes. Each 8-bit extension to ASCII differs from the rest. For characters represented by the 7-bit ASCII character codes, the UTF-8 representation is exactly equivalent to ASCII, allowing transparent round trip migration.
Does UTF-8 support all languages?
UTF-8 supports any unicode character, which pragmatically means any natural language (Coptic, Sinhala, Phonecian, Cherokee etc), as well as many non-spoken languages (Music notation, mathematical symbols, APL). The stated objective of the Unicode consortium is to encompass all communications.