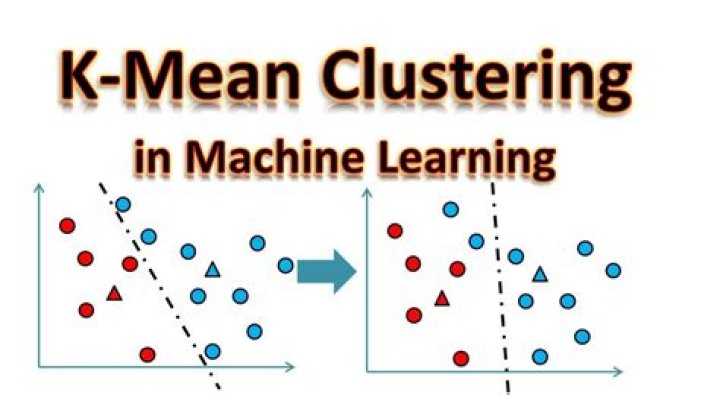
k-modes is an extension of k-means. Instead of distances it uses dissimilarities (that is, quantification of the total mismatches between two objects: the smaller this number, the more similar the two objects). We will have as many modes as the number of clusters we required, since they act as centroids.
How does K modes clustering work?
KModes clustering is one of the unsupervised Machine Learning algorithms that is used to cluster categorical variables. So we go for KModes algorithm. It uses the dissimilarities(total mismatches) between the data points. The lesser the dissimilarities the more similar our data points are.
How do you use k-means in categorical data?
The k-Means algorithm is not applicable to categorical data, as categorical variables are discrete and do not have any natural origin. So computing euclidean distance for such as space is not meaningful.
What is K prototype clustering?
K-Prototype is a clustering method based on partitioning. Its algorithm is an improvement of the K-Means and K-Mode clustering algorithm to handle clustering with the mixed data types. Read the full of K-Prototype clustering algorithm HERE. It’s important to know well about the scale measurement from the data.
How do you use K modes?
Step for K-Modes clustering algorithm:
- Randomly select k unique objects as the initial cluster centers (modes).
- Calculate the distances between each object and the cluster mode; assign the object to the cluster whose center has the shortest distance.
- Repeat until all objects are assigned to clusters.
What is elbow method in K-means?
The elbow method runs k-means clustering on the dataset for a range of values for k (say from 1-10) and then for each value of k computes an average score for all clusters. By default, the distortion score is computed, the sum of square distances from each point to its assigned center.
How do you interpret K means?
It calculates the sum of the square of the points and calculates the average distance. When the value of k is 1, the within-cluster sum of the square will be high. As the value of k increases, the within-cluster sum of square value will decrease.
Which of the following are required by k-means clustering?
Explanation: K-means requires a number of clusters. Explanation: Hierarchical clustering requires a defined distance as well. 10. K-means is not deterministic and it also consists of number of iterations.
How do you use K prototype?
Here are the simple steps of the K-prototype algorithm
- Select k initial prototypes from the dataset X.
- Allocate each object in X to a cluster whose prototype is the nearest to it.
- After all, objects have been allocated to a cluster, retest the similarity of objects against the current prototypes.
Which is needed by K-means clustering?
What is K-means algorithm with example?
K-means clustering algorithm computes the centroids and iterates until we it finds optimal centroid. In this algorithm, the data points are assigned to a cluster in such a manner that the sum of the squared distance between the data points and centroid would be minimum.
How do you interpret K-means?
What are k-modes and why are they important?
This is the mode of the responses -the most common answer – which is where the name K-modes comes from. So each centroid is in the same form as the original questionnaire data – a set of responses to the different questions – rather than a 40-dimensional vector.
How to perform k-modes clustering on categorical data?
Perform k-modes clustering on categorical data. A matrix or data frame of categorical data. Objects have to be in rows, variables in columns. Either the number of modes or a set of initial (distinct) cluster modes. If a number, a random set of (distinct) rows in data is chosen as the initial modes.
What is the \\(K\\)-modes algorithm?
The \\ (k\\)-modes algorithm (Huang, 1997) an extension of the k-means algorithm by MacQueen (1967). The data given by data is clustered by the \\ (k\\)-modes method (Huang, 1997) which aims to partition the objects into \\ (k\\) groups such that the distance from objects to the assigned cluster modes is minimized.
What does the kmodes function return?
Well, the kmodes function returns you a list, with the most interesting entries being: cluster: A vector of integers indicating the cluster to which each object is allocated. size: The number of objects in each cluster. modes: A matrix of cluster modes.