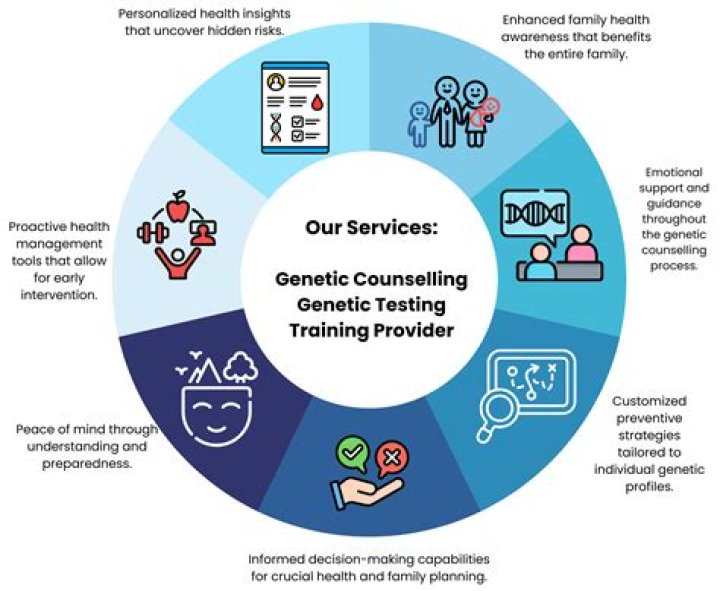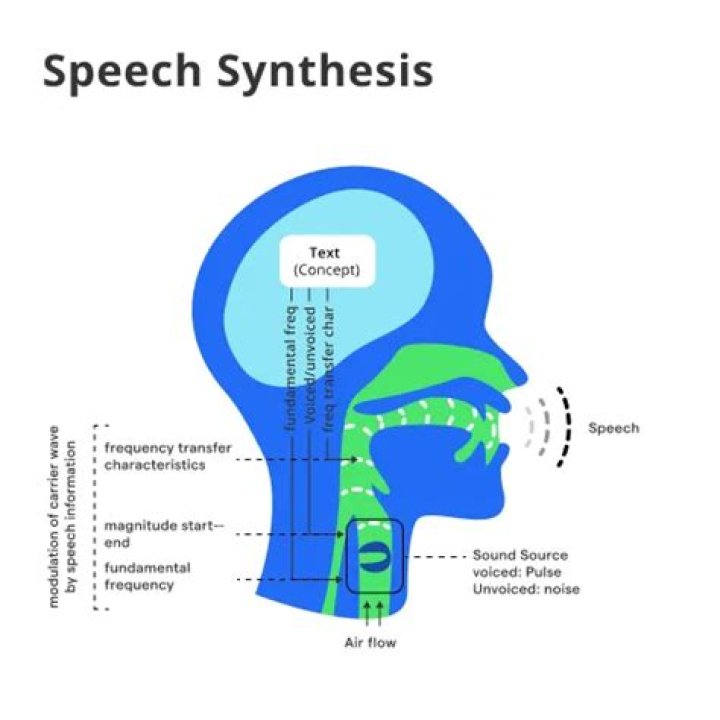
The most important qualities of a speech synthesis system are naturalness and intelligibility. Naturalness describes how closely the output sounds like human speech, while intelligibility is the ease with which the output is understood. The ideal speech synthesizer is both natural and intelligible.
What are the techniques used in the voice conversion process?
Voice conversion involves multiple speech processing techniques, such as speech analysis, spectral conversion, prosody conversion, speaker characterization, and vocoding.
Can we generate emotional pronunciations for expressive speech synthesis?
The analysis of emotional pronunciations reveals strong dependencies between prosody and phoneme assimilation or elisions. According to perceptual tests, the double adaptation allows to synthesize expressive speech samples of good quality, but emotion-specific pronunciations are too subtle to be perceived by testers.
What is speech synthesis in NLP?
speech synthesis • speech recognition. One particular form of each involves written text at one end of the process and speech at the other, i.e. • text-to-speech or TTS • speech-to-text or STT.
Which of the following is a feature of speech synthesis select the one best answer?
Answer: c) It allows your computer to convert text to audio. Explanation: A text-to-speech (TTS) system converts normal language text into speech; other systems render symbolic linguistic representations like phonetic transcriptions into speech.
What are the methods of speech synthesis?
In the overview by Furui (1989), synthesis techniques are divided into three main classes: waveform coding, analysis-synthesis, and synthesis by rule. The analysis-synthesis method is defined as a method in which human speech is transformed into parameter sequences, which are stored.
What do you mean by speech synthesis and speech recognition features?
Speech synthesis is being used in programs where oral communication is the only means by which information can be received, while speech recognition is facilitating commu- nication between humans and computers, whereby the acoustic voice signals changes in the sequence of words making up a written text.
Is speech synthesis input or output?
The process of translating text input into audio data is called synthesis and the output of synthesis is called synthetic speech. Text-to-Speech takes two types of input: raw text or SSML-formatted data (discussed below). To create a new audio file, you call the synthesize endpoint of the API.
What is a synthesis speech?
Speech synthesis (TTS) is defined as the artificial production of human voices. The main use (and what induced its creation) is the ability to translate a text into spoken speech automatically.
What type of audio format supports speech synthesis?
Formats supported: Users won’t find any difficulty in playing the downloaded audio as the same is supported in multiple formats like wav, mp3, ogg, wma, aiff, alaw, ulaw, vox and mp4.
What does speech synthesis software do?
Speech synthesis is the computer-generated simulation of human speech. It is used to translate written information into aural information where it is more convenient, especially for mobile applications such as voice-enabled e-mail and Unified messaging .
What two capabilities does speech recognition software give you?
Speech recognition technology allows computers to take spoken audio, interpret it and generate text from it.